Power Automate Desktop for Windows 10のシリーズ、前回は[Web オートメーション]の2つのアクションを確認しました。
今回はOCRのアクションを確認してみます。OCRは画像から文字を認識してくれる便利なやつです。(2021/3/19時点、バージョン2.6.00158.21069に基づいた内容になりますので予めご了承ください。)
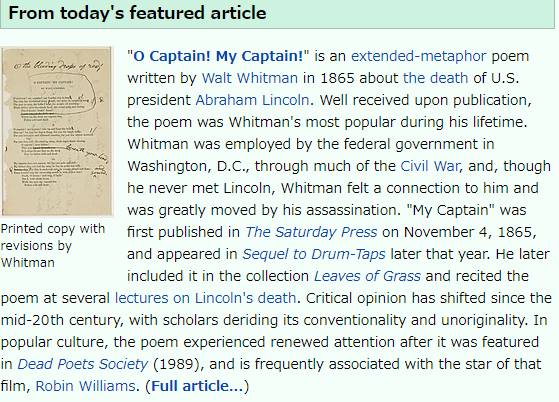
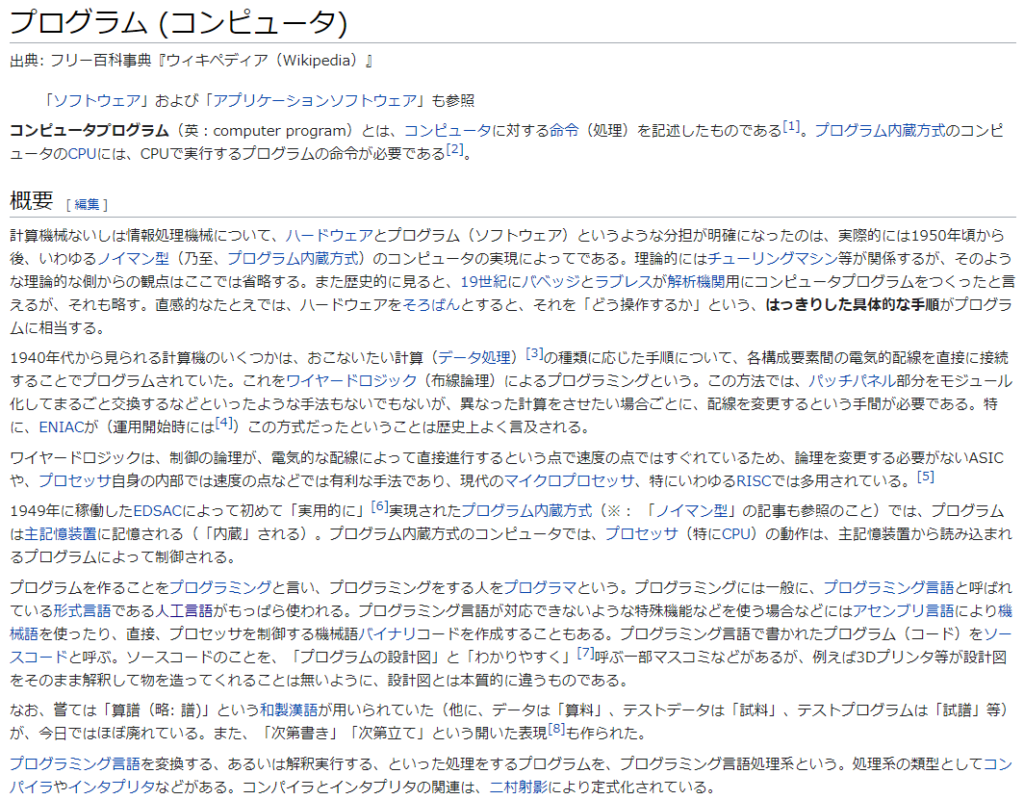
OCRに使用した画像
WikiぺディアからOCRに使用する画像を借用しました。
Tesseract OCR のインストール
Tesseract OCRが未インストールの場合は、インストールを実施しておいてください。「Tesseract OCR windows インストール」で検索すると、いろいろ情報が見つかると思いますので、詳細は割愛します。
フロー作成
それではフローを作成していきましょう。
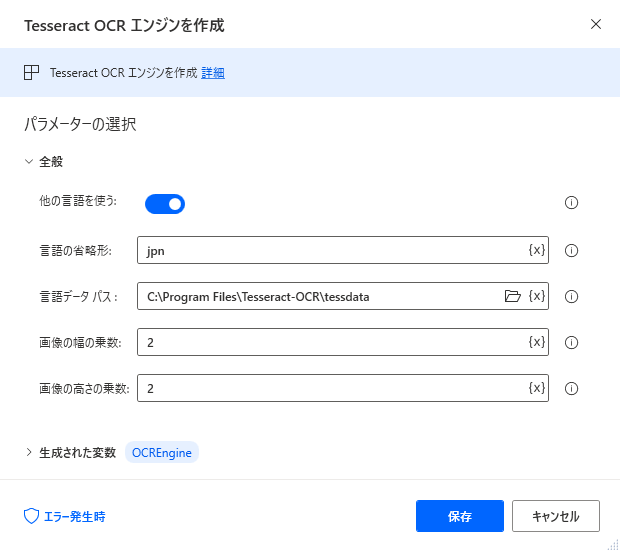
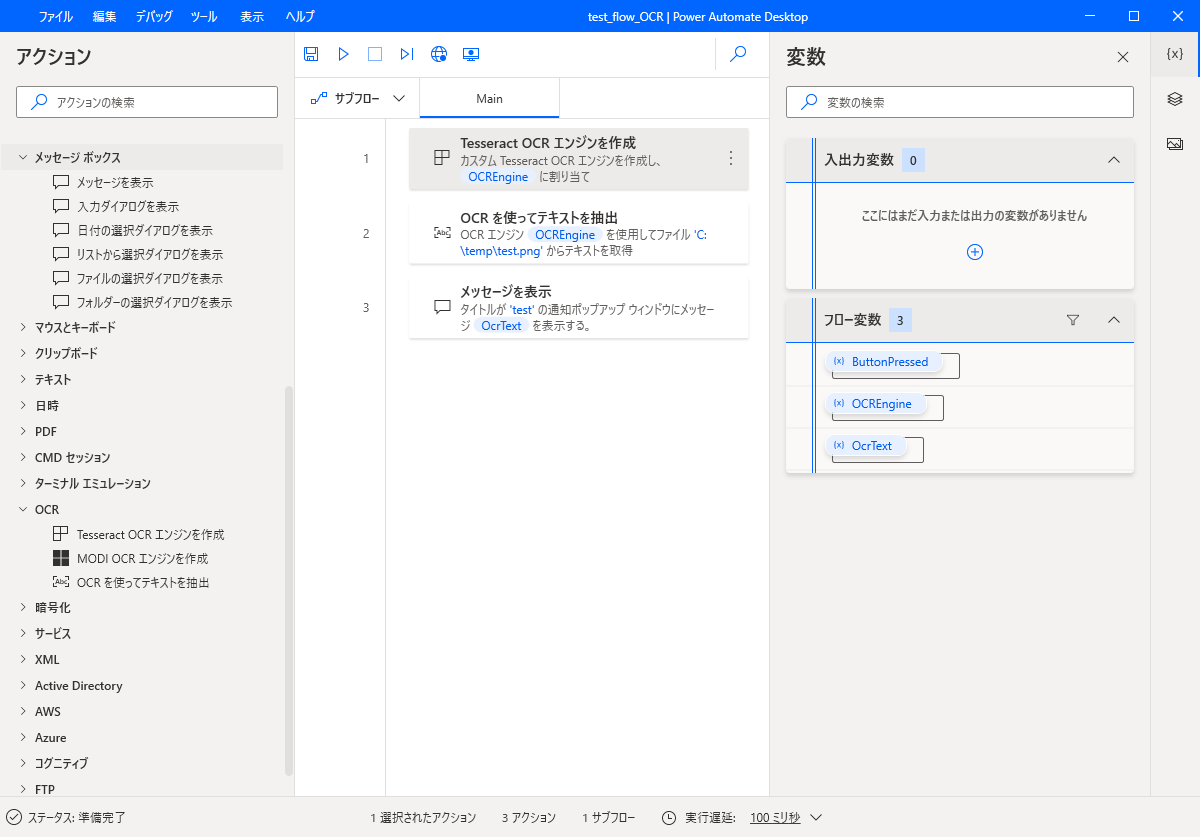
「Tesseract OCR エンジンを作成」のアクションを設定します。
「他の言語を使う」をオンにして、日本語を指定します。
言語データパスはインストール先のフォルダ内にあります。(jpnなんちゃらというファイルがあるフォルダになります。)
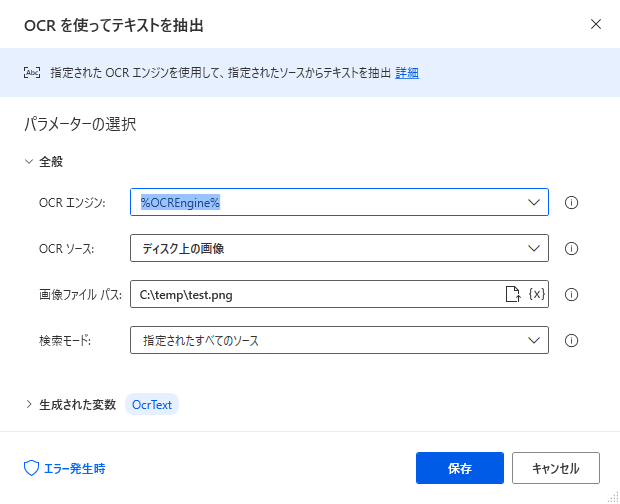
「OCRを使ってテキストを抽出」のアクションを設定します。
ここでは、OCRソースとして、ディスク上の画像を指定しました。
検索モードで、OCR対象の特定領域を指定する事が可能です。ここでは画像全体を認識するように指定しました。
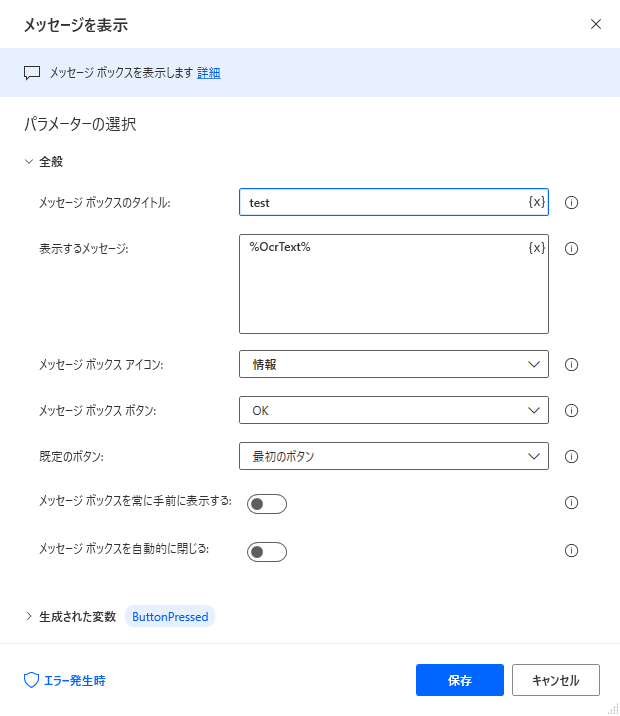
「メッセージを表示」のアクションを設定します。
フロー全体の様子はこんな感じになります。
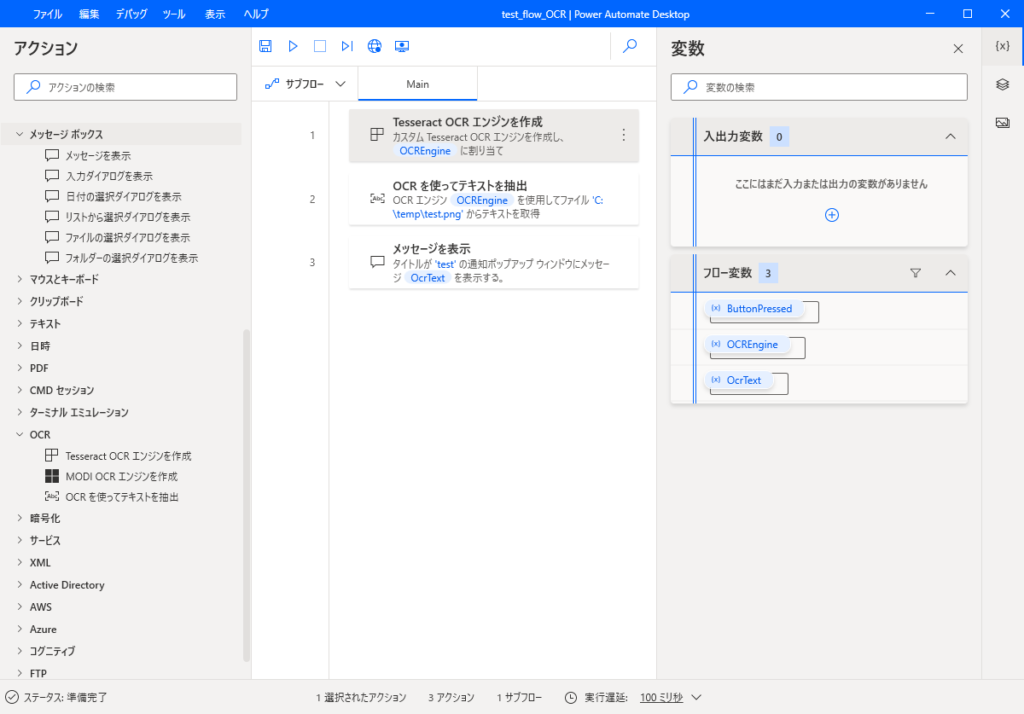
フローの実行
英語の画像を読み込ませてみました。どうでしょうか。割と認識されていますね。

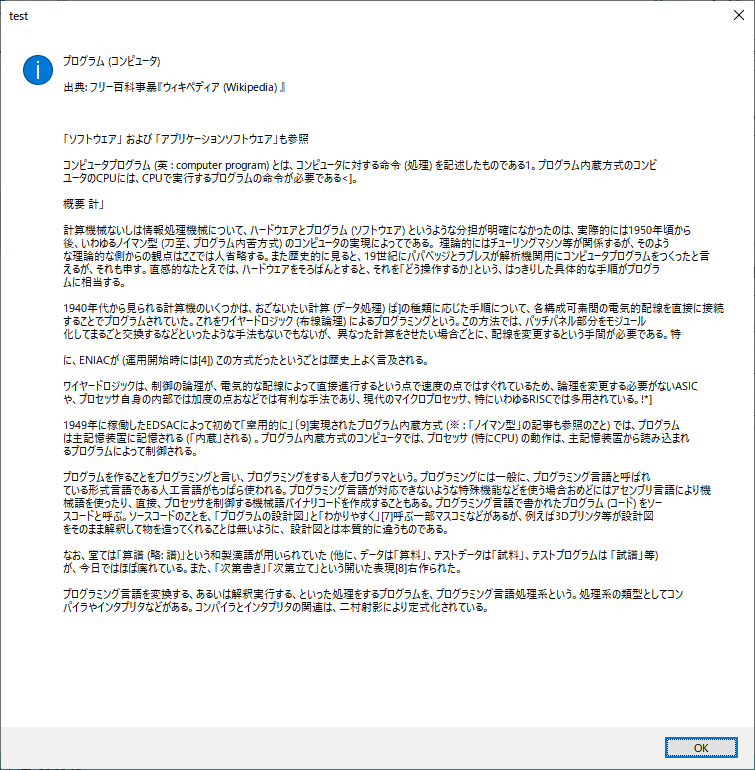
日本語の画像を読み込ませてみました。こちらも割と認識されていますね。なお、手書きの画像ファイルの認識精度はいまいちでした。(自分の字が汚いので)
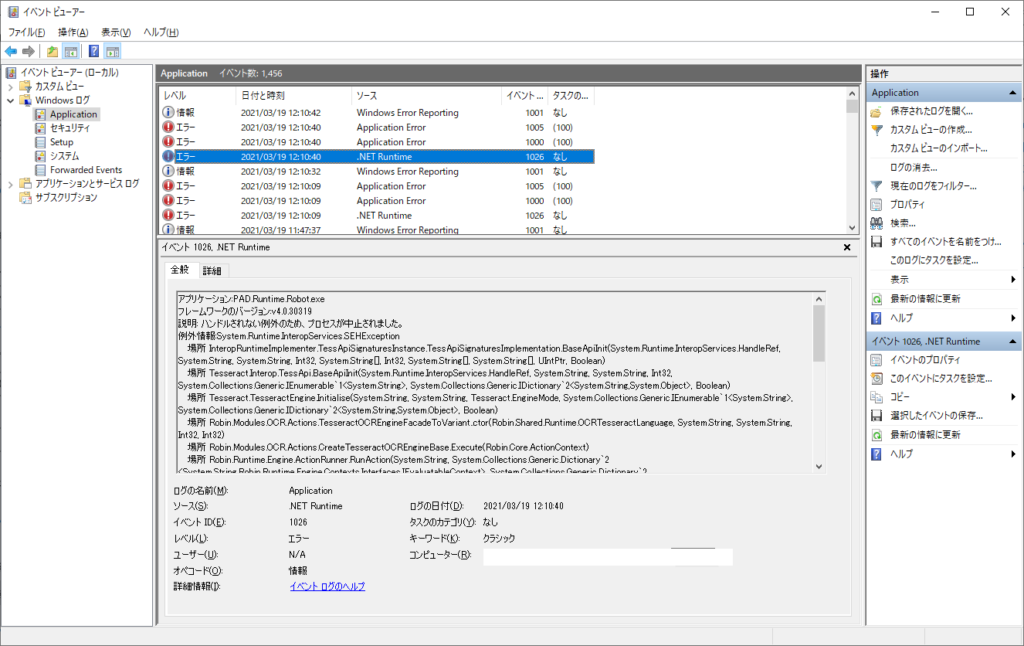
実はOCR実行がうまく行かなかったパターンもありました
フローの実行を行っても、結果が何も表示されない場合がありました。
イベントを見るとアプリケーションエラーが記録されていました。chkdskを実行してみて。というイベントもありましたので、ディスク周りですかね。
違うパソコン上で実行したらうまく動作したので、何か原因があるかもしれません。元々、このイベントが記録されたパソコンはmacbookにWindows10をインストールしたものなので環境が変なのかもしれません。
うまく実行されないという場合は、イベントビューアーを確認するのも良いと思います。
まとめ
今回は[OCR]のアクションを確認しました。
- [OCR]
- [Tesseract OCR エンジンを作成]
- [OCRを使ってテキストを抽出]
環境が変じゃなければ、割と簡単にOCR機能を試す事ができますね。手書きの文字は厳しい感じがしましたが、画像や画面上の文字で試してみてください。
良かったら他の記事も読んで頂けると嬉しいです。