Power Automate Desktop for Windows 10のシリーズ、前回は[OCR]のアクションを確認しました。
今回はPDFファイルからテキストを抽出するという内容です。
(2021/4/13時点、バージョン2.6.00158.21069に基づいた内容になりますので予めご了承ください。)
使用したPDF
経済産業省の「長野県の地域経済分析」の資料を借用しました。
https://www.meti.go.jp/policy/local_economy/bunnseki/47bunseki/20nagano.pdf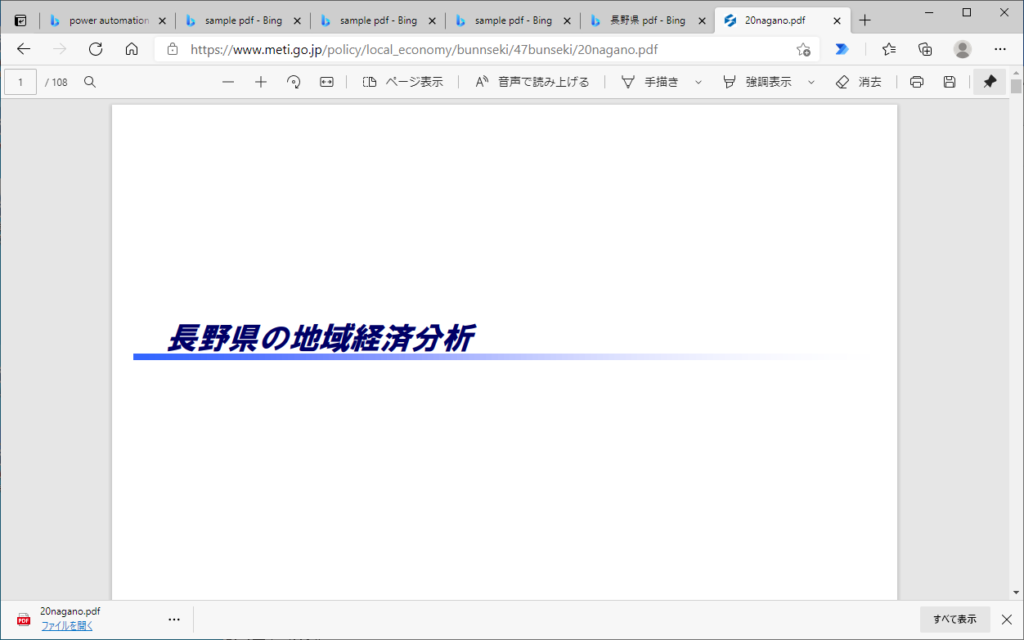
フロー作成
それではフローを作成していきましょう。
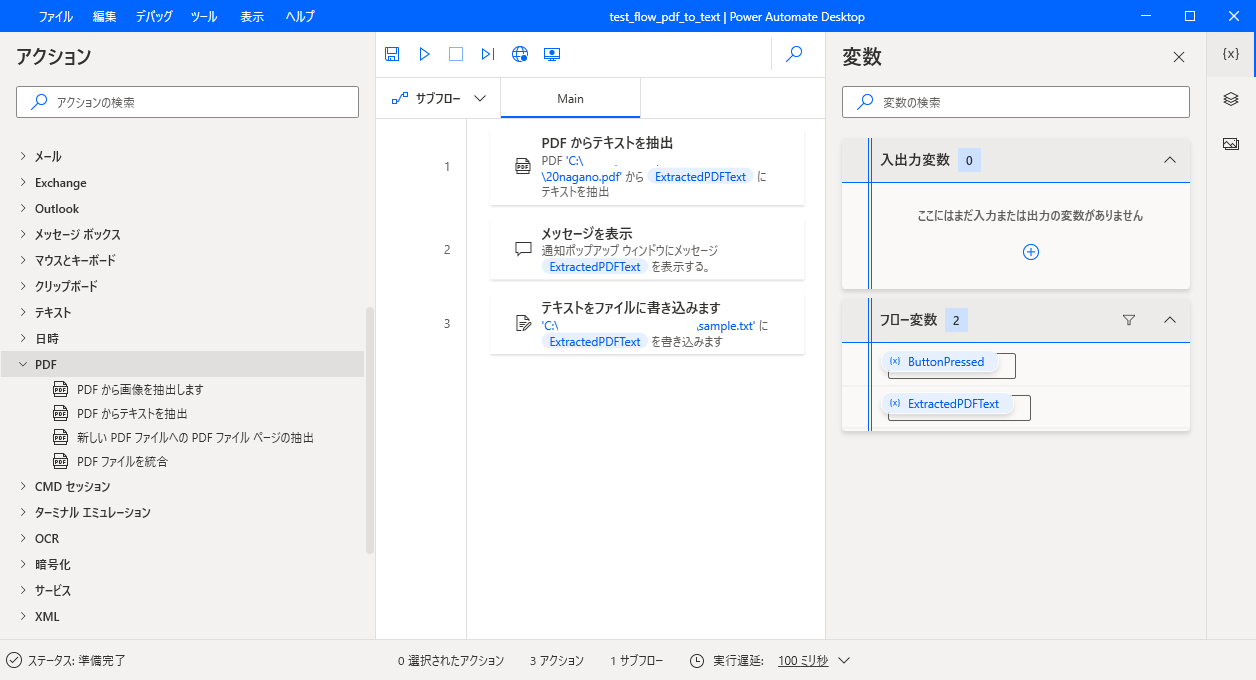
PDFからテキストを抽出
「PDFからテキストを抽出」のアクションを設定します。
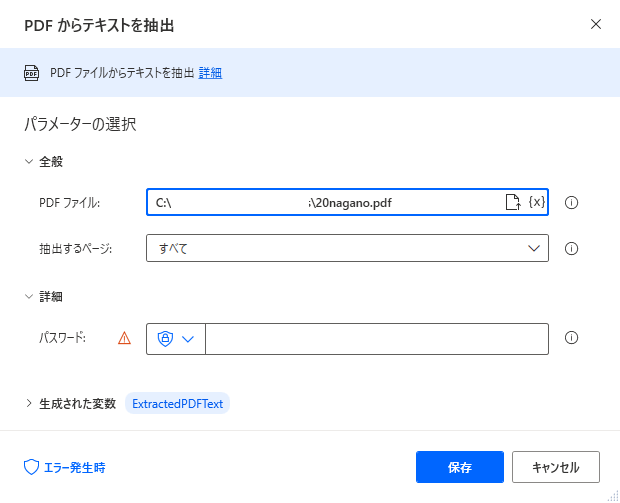
PDFファイルの欄で対象のファイルを選択します。
抽出するページは「すべて」で行いましたが、ページ指定や範囲指定が可能です。
パスワードが掛かっているPDFファイルの場合はパスワードを指定可能のようです。
これで変数「ExtractedPDFText」という変数に内容が入ります。
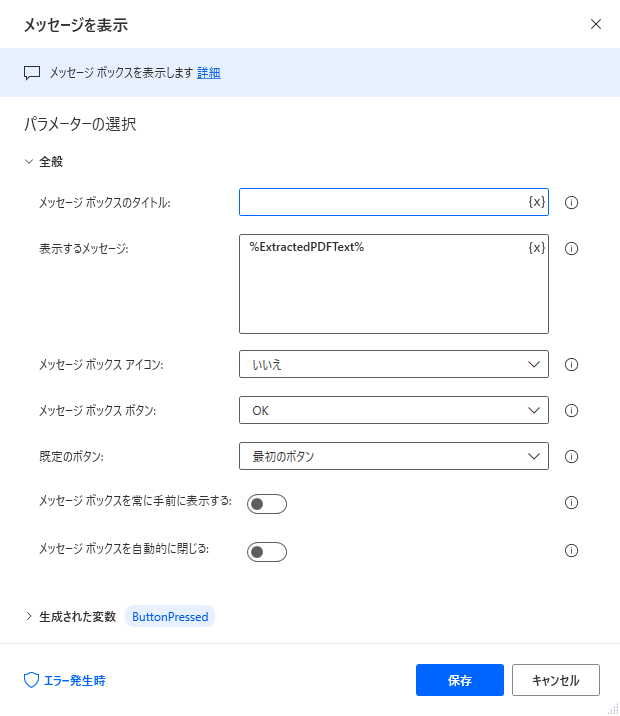
メッセージを表示
「ExtractedPDFText」の内容を表示させてみます。これは表示するメッセージのところで、変数を指定するだけです。
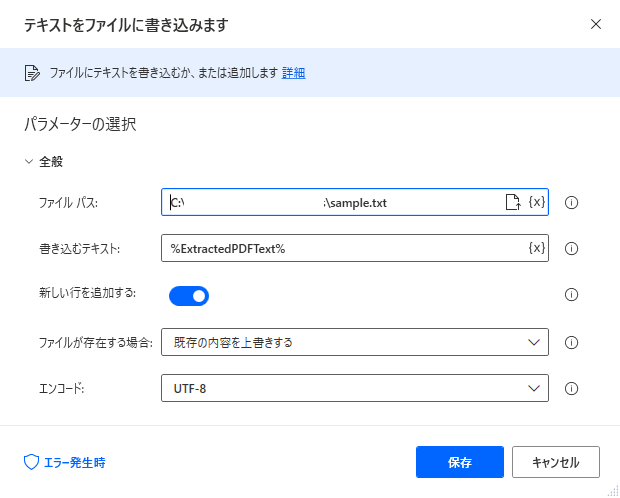
テキストをファイルに書き込みます
結果をテキストファイルに書き込んでみます。ファイルパスと変数を指定するだけです。
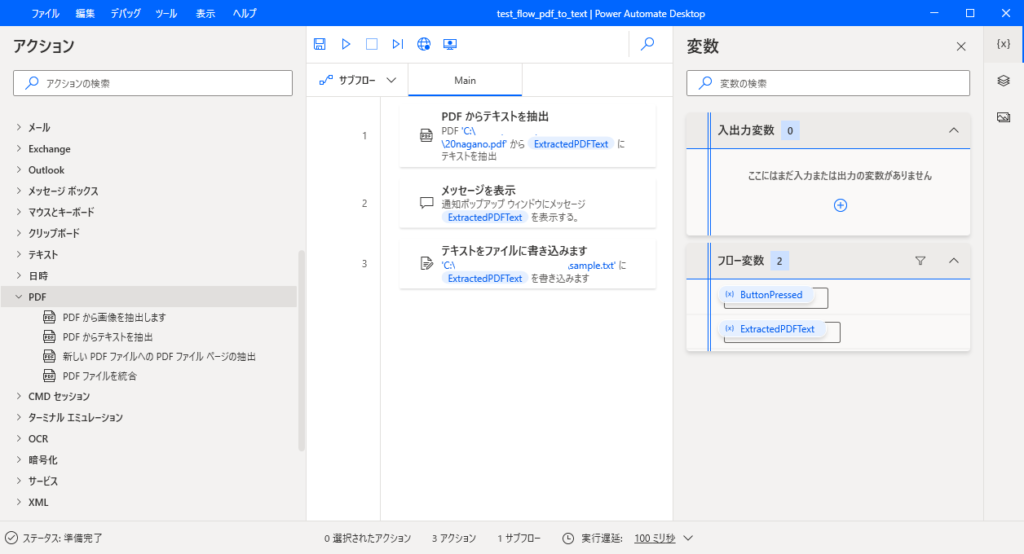
フロー全体の様子
フロー全体の様子はこんな感じになります。
フローの実行
フローを実行すると、無事テキストが抽出されました。
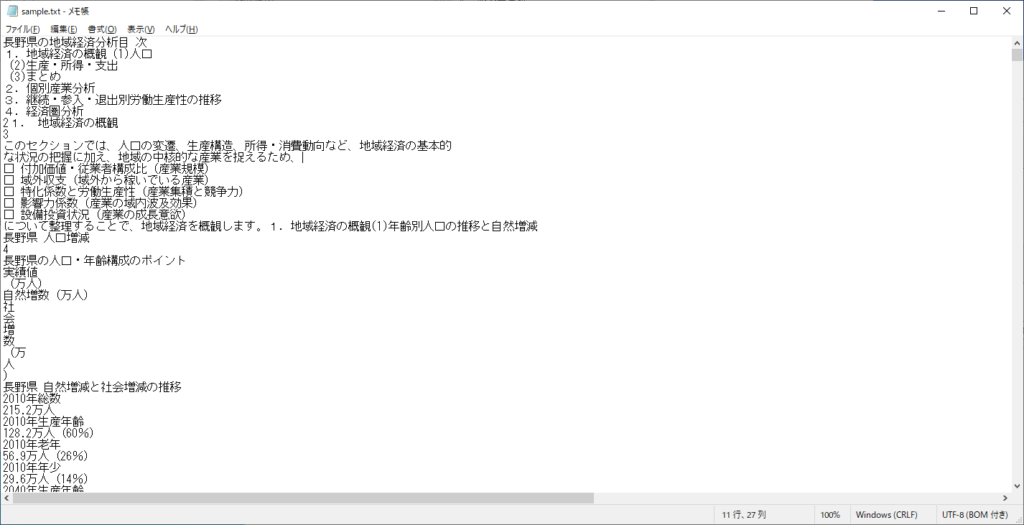
まとめ
今回は[PDF]のアクションを確認しました。
Wordが使える方は、PDFファイルをWordで開くと自動的に変換されるので、そちらの方が便利かもしれませんね。利用シーンに合わせてご検討ください。
良かったら他の記事も読んで頂けると嬉しいです。
短期連載